
Bine ați revenit, dragii mei ethical hackers!
Recent, am demonstrat un hack în care, dacă doriți, ați putea redirecționa traficul destinat pentru un site, pe site-ul dvs. fals. Desigur, pentru a face acest lucru cu adevărat, ar trebui să faceți o replică a site-ului pe care l-ați clonat, sau mai bine, puteți pur și simplu să faceți o copie a site-ului original și să îl găzduiți pe serverul propriu.
HTTrack este instrumentul cel mai potrivit pentru a face acest lucru. HTTrack accesează orice site web și face o copie a acestuia pe hard disk. Acest lucru poate fi util pentru căutarea datelor pe site-ul offline, cum ar fi adresele de e-mail, informații utile pentru ingineria socială, fișierele de parolă ascunse (credeți-mă, am găsit câteva), proprietatea intelectuală sau poate replicarea unei pagini de conectare pentru un Evil Twin,cu scopul de a captura date de logare. Din fericire, HTTrack este inclus în Black|Web, așa că îl putem folosi din distribuția noastră de hacking preferată
Pasul 1: Utilizăm HTTrack
Acum, o să începem prin căutarea fișierului de ajutor pentru acesta. Când am instalat HTTrack în Black|Web, l-am plasat în directorul /usr/bin, deci ar trebui să fie accesibil din orice director Black|Web, deoarece /usr/bin este în variabila PATH. Să tastăm:
httrack –help

Am subliniat linia de sintaxă principală din captura de ecran de mai sus. Sintaxa de bază este următoarea, unde -O reprezintă “ieșirea”. Acest comutator indică HTTrack-ului unde să trimită site-ul web.
httrack <URL-ul site-ului> [orice opțiune] Filtrul URL -O <locația unde trimitem copia>
Utilizarea HTTrack este destul de simplă. Trebuie doar să o îndreptăm către site-ul pe care dorim să îl copiem și apoi să direcționăm ieșirea (-O) într-un director de pe hard disk-ul nostru, unde dorim să stocăm site-ul web. Puțină atenție, aici. Unele site-uri sunt uriașe. Dacă încercați să copiați Facebook-ul pe hard disk, vă pot garanta că nu aveți suficient spațiu, deci îl lăsați doar puțin pornit.
Pasul 2: Testăm HTTrack
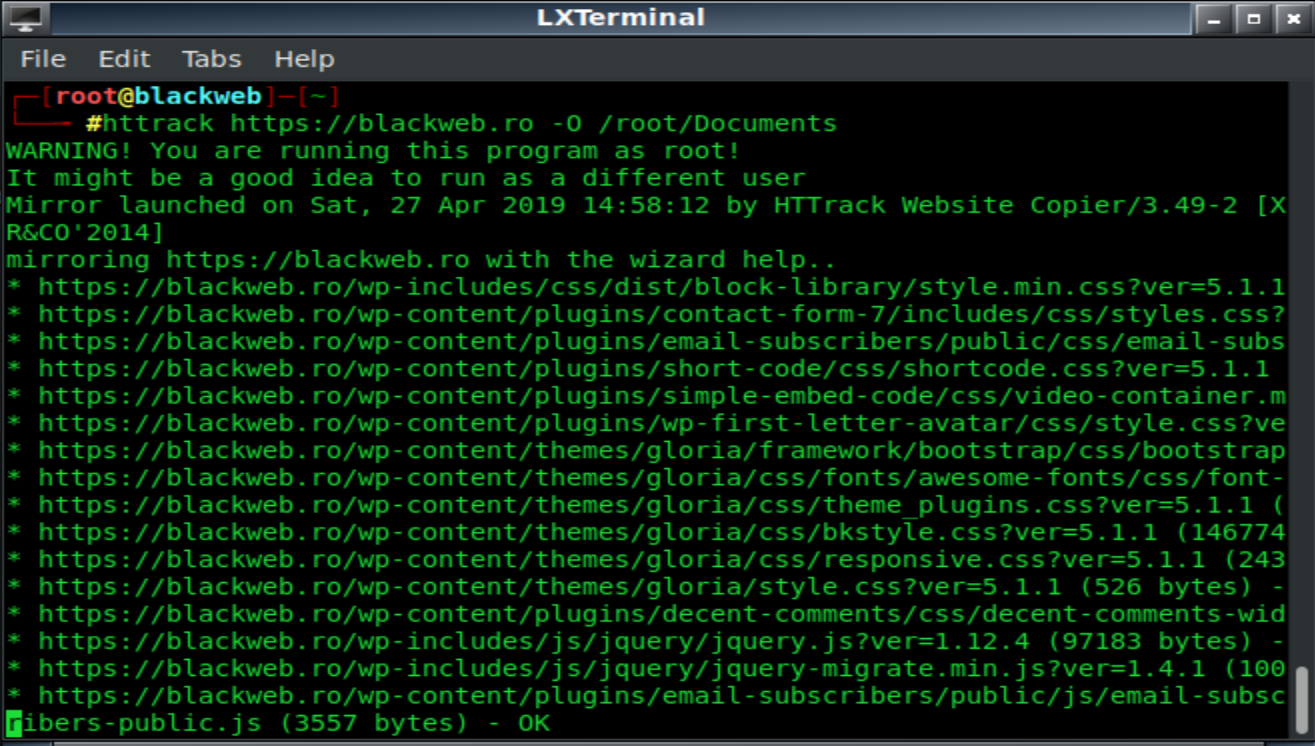
În acest test, noi o să facem copia unui site deținut de noi, adică blackweb.ro
- httrack https://blackweb.ro -O /root/Documents

După cum puteți vedea, am făcut o copie a tuturor paginilor acestui site pe hard disk-ul nostru.
Pasul 3: Aruncăm o privire prin copia site-ului
Acum, că am capturat și copiat întregul site pe hard disk, să aruncăm o privire pe el. Putem deschide browserul Mozilla (sau orice browser) și vom vedea conținutul site-ului copiat în locația de pe hard disk. Din moment ce am copiat site-ul web în /root/Documents, pur și simplu îl indicăm browserului și putem vizualiza tot conținutul site-ului. Dacă ne îndreptăm spre /root/Documents/www.blackweb.ro/wp-login, putem vedea că avem o copie exactă a paginii de conectare.


Hmmm … ce am putea folosi din asta?
Dacă încercați să găsiți informații despre o anumită companie pentru ingineria socială sau încercați să clonați un site și aveți nevoie de pagina de logare, HTTrack este un instrument excelent pentru aceste sarcini. Știu că acest tutorial poate părea unul absurd la prima vedere, însă tutorialul care îl urmează, alături de un alt tutorial scris deja pe blackweb, va face puțină lumină, despre cât de util este acest tool.
Cam atât cu acest tutorial. Nu uitați să reveniți pentru mai multe ghiduri. Dacă aveți nelămuriri, secțiunea comentarii vă stă la dispoziție. Până data viitoare, să ne citim cu bine! 🙂




